import openpyxl
from openpyxl.styles import PatternFill
import time
import os
import re
import requests
from openai import AzureOpenAI
AUTO_TRANSLATE_FILL = PatternFill(
start_color="FFD8E4BC",
end_color="FFD8E4BC",
fill_type="solid"
)
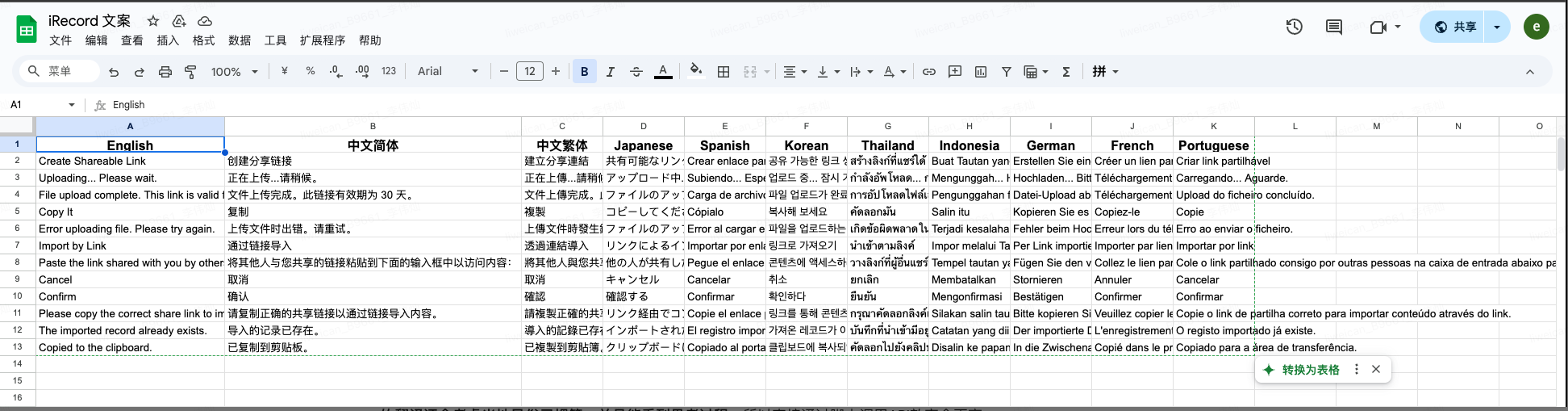
LANGUAGE_MAPPING = {
"中文简体": "Simplified Chinese",
"中文繁体": "Traditional Chinese",
"Japanese": "Japanese",
"Spanish": "Spanish",
"Korean": "Korean",
"Thailand": "Thai",
"Indonesia": "Indonesian",
"German": "German",
"French": "French",
"Portuguese": "Portuguese"
}
DEEPSEEK_API_URL = os.getenv("DEEPSEEK_API_URL")
DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY")
DEEPSEEK_MODEL_NAME = "deepseek-ai/DeepSeek-R1-Distill-Qwen-14B"
AZURE_OPENAI_ENDPOINT = os.getenv("AZURE_OPENAI_ENDPOINT")
AZURE_OPENAI_API_KEY = os.getenv("AZURE_OPENAI_API_KEY")
GPT_API_VERSION = "2024-06-01"
BATCH_SIZE = 8
MAX_TOKENS = 4096
def parse_translation_result(raw_text, texts):
translated = []
pattern = re.compile(r'^\d+\.\s*(.+)$', re.MULTILINE)
matches = pattern.findall(raw_text)
if len(matches) == len(texts):
translated = [m.strip() for m in matches]
else:
translated = [line.split(". ", 1)[-1].strip()
for line in raw_text.split("\n")
if line.strip() and line[0].isdigit()]
return translated
def batch_translate(texts, target_lang, model_choice):
if not texts or not target_lang:
return []
numbered_texts = "\n".join([f"{i + 1}. {text}" for i, text in enumerate(texts)])
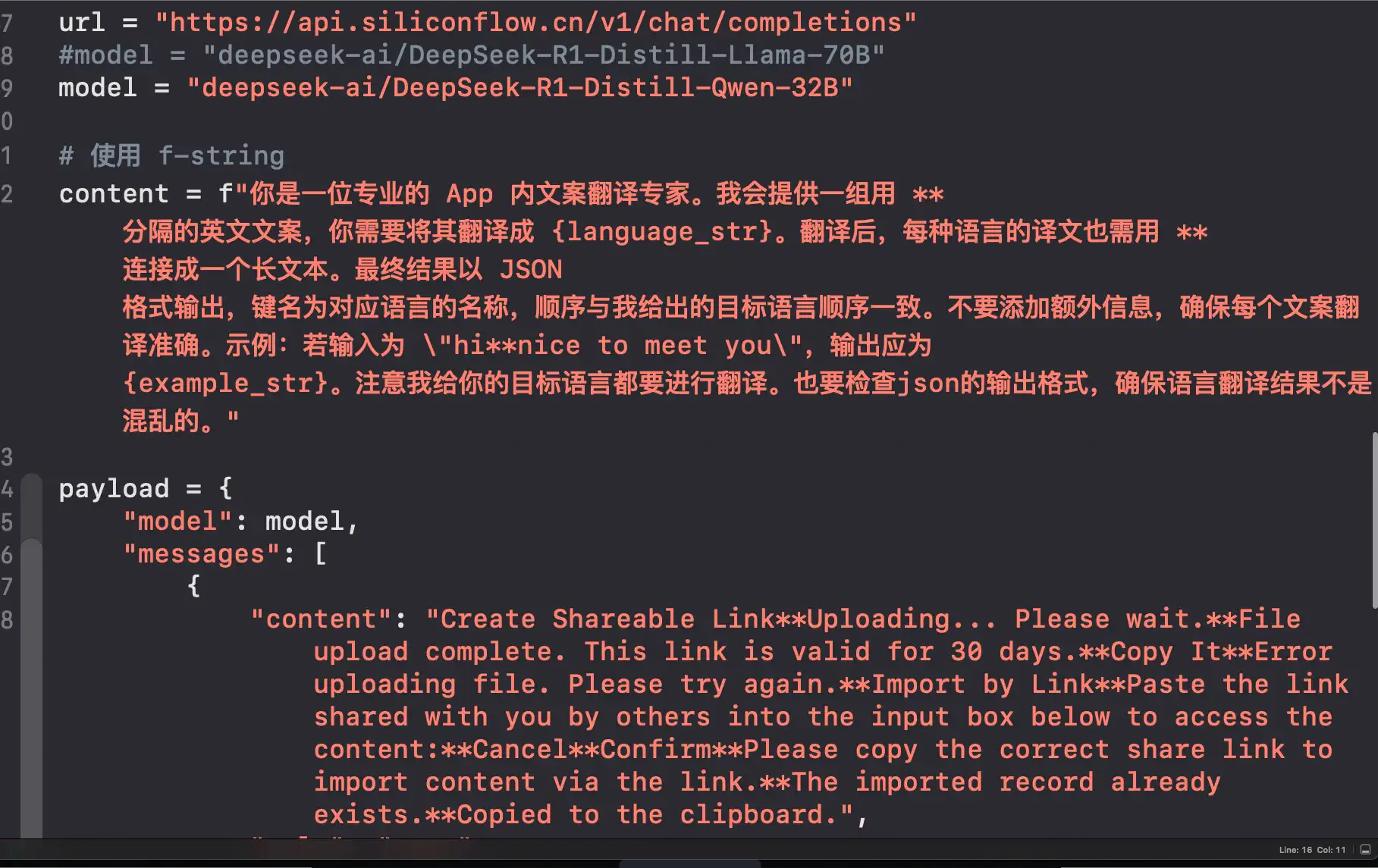
system_prompt = f"""你是一位专业App内文案翻译人员,请将以下英文文本列表准确翻译为{LANGUAGE_MAPPING[target_lang]}:
{numbered_texts}
请严格遵循:
1. 保持专业术语一致性
2. 保留数字和特殊符号,${{TT}}、${{time}}等是占位符均不翻译。
3. 使用正式书面语体
4. 按以下格式返回:
1. 翻译结果
2. 翻译结果"""
if model_choice == "deepseek":
payload = {
"model": DEEPSEEK_MODEL_NAME,
"messages": [
{"role": "system", "content": system_prompt},
{"role": "user", "content": "请开始翻译"}
],
"temperature": 0,
"max_tokens": MAX_TOKENS
}
headers = {
"Authorization": f"Bearer {DEEPSEEK_API_KEY}",
"Content-Type": "application/json"
}
try:
print(system_prompt)
print("🚀🚀🚀当前DeepSeek模型是" + DEEPSEEK_MODEL_NAME)
response = requests.post(DEEPSEEK_API_URL, json=payload, headers=headers, timeout=(10, 30))
response.raise_for_status()
print(f"API响应状态码: {response.status_code}")
try:
response_data = response.json()
print(response_data)
except ValueError:
raise Exception("无效的JSON响应")
if 'choices' not in response_data or not response_data['choices']:
raise Exception("API返回结构异常")
raw_text = response_data['choices'][0]['message']['content']
translated = parse_translation_result(raw_text, texts)
print(translated)
return translated
except Exception as e:
print(f"API调用失败: {str(e)}")
return []
elif model_choice == "gpt":
client = AzureOpenAI(
azure_endpoint=AZURE_OPENAI_ENDPOINT,
api_key=AZURE_OPENAI_API_KEY,
api_version=GPT_API_VERSION
)
try:
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": "请开始翻译"}
]
)
raw_text = response.choices[0].message.content
translated = parse_translation_result(raw_text, texts)
print(translated)
return translated
except Exception as e:
print(f"API调用失败: {str(e)}")
return []
def process_excel(input_path, output_path, model_choice):
print(f"开始读取Excel {input_path}")
print(f"当前使用的大模型是: {model_choice.upper()}")
try:
wb = openpyxl.load_workbook(input_path)
sheet = wb.active
source_col = None
for idx, cell in enumerate(sheet[1], 1):
if cell.value and cell.value.strip() == "English":
source_col = idx
break
if not source_col:
raise ValueError("工作表中未找到'English'列,请检查第一行标题")
for col_idx in range(1, sheet.max_column + 1):
header_cell = sheet.cell(row=1, column=col_idx)
if not header_cell.value:
continue
lang_name = header_cell.value.strip()
if lang_name == "English" or lang_name not in LANGUAGE_MAPPING:
continue
print(f"\n=== 正在处理 {lang_name} ===")
process_language_column(sheet, source_col, col_idx, lang_name, model_choice)
wb.save(output_path)
print(f"\n处理完成!文件已保存至:{output_path}")
except Exception as e:
print(f"处理过程中发生错误: {str(e)}")
raise
def process_language_column(sheet, source_col, target_col, lang_name, model_choice):
"""处理单个语言列"""
batch_texts = []
batch_positions = []
for row_idx in range(2, sheet.max_row + 1):
source_cell = sheet.cell(row=row_idx, column=source_col)
target_cell = sheet.cell(row=row_idx, column=target_col)
if not source_cell.value or (target_cell.value and str(target_cell.value).strip()):
continue
batch_texts.append(str(source_cell.value).strip())
batch_positions.append((row_idx, target_col))
if len(batch_texts) >= BATCH_SIZE:
process_batch(sheet, batch_texts, batch_positions, lang_name, model_choice)
batch_texts.clear()
batch_positions.clear()
if batch_texts:
process_batch(sheet, batch_texts, batch_positions, lang_name, model_choice)
def process_batch(sheet, texts, positions, lang_name, model_choice):
print(f"正在批量翻译 {len(texts)} 条文本到 {lang_name}")
translated = []
for retry in range(3):
try:
translated = batch_translate(texts, lang_name, model_choice)
if len(translated) == len(texts):
break
print(f"第{retry + 1}次重试...")
time.sleep(2 ** retry)
except Exception as e:
print(f"批处理失败: {str(e)}")
if len(translated) != len(texts):
print(f"未能获取完整翻译,预期{len(texts)}条,实际{len(translated)}条")
translated += [f"[翻译失败] {text}" for text in texts[len(translated):]]
for (row, col), text in zip(positions, translated):
cell = sheet.cell(row=row, column=col)
cell.value = text
cell.fill = AUTO_TRANSLATE_FILL
if __name__ == '__main__':
import sys
if len(sys.argv) > 1 and sys.argv[1] not in ["deepseek", "gpt"]:
print("请指定有效的模型,可选值为 [deepseek|gpt],默认使用gpt。")
sys.exit(1)
model_choice = sys.argv[1] if len(sys.argv) > 1 else "gpt"
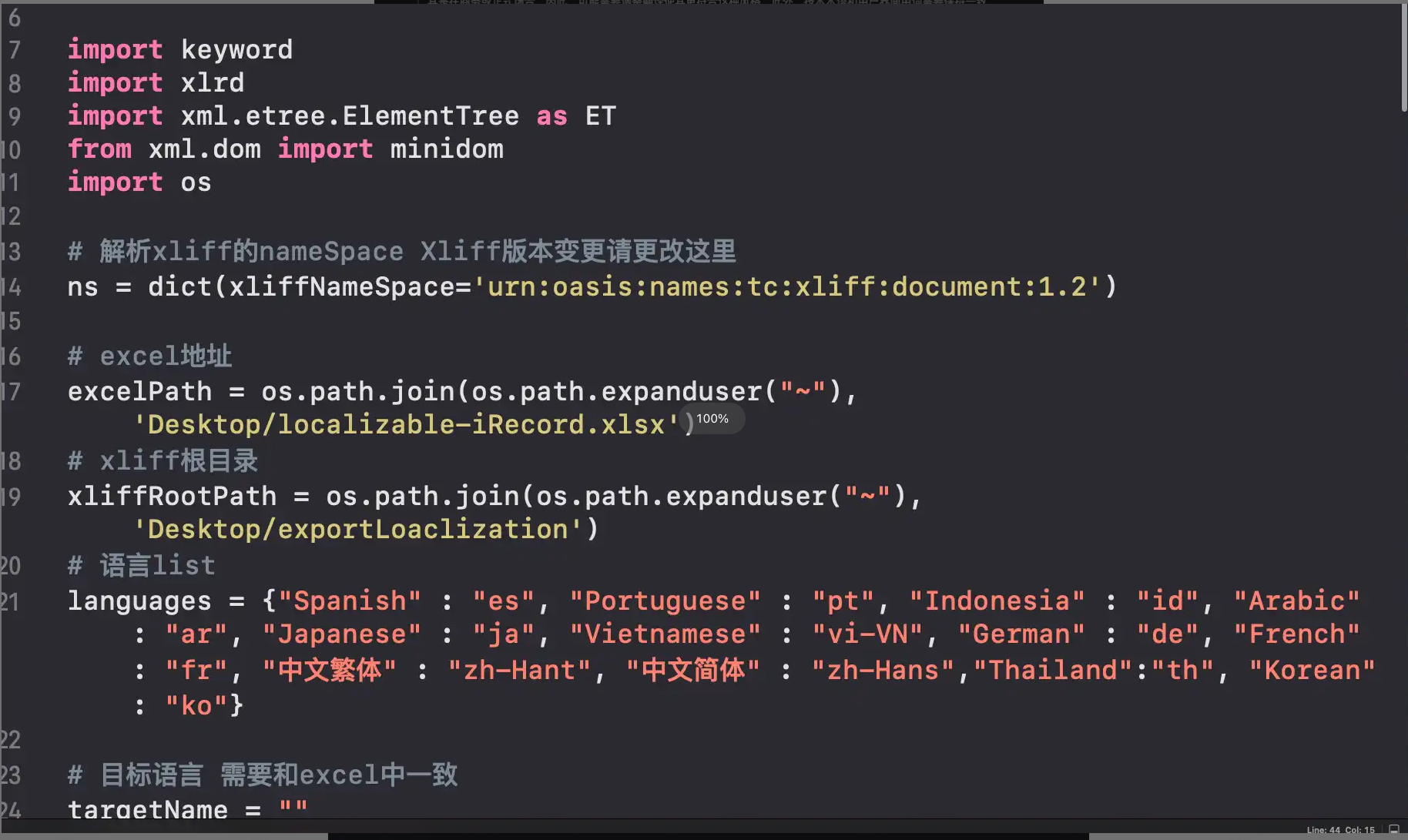
input_file = os.path.expanduser('~/Desktop/test2.xlsx')
output_file = os.path.expanduser('~/Desktop/translated_output.xlsx')
try:
process_excel(input_file, output_file, model_choice)
except Exception as e:
print(f"运行失败: {str(e)}")
exit(1)
|