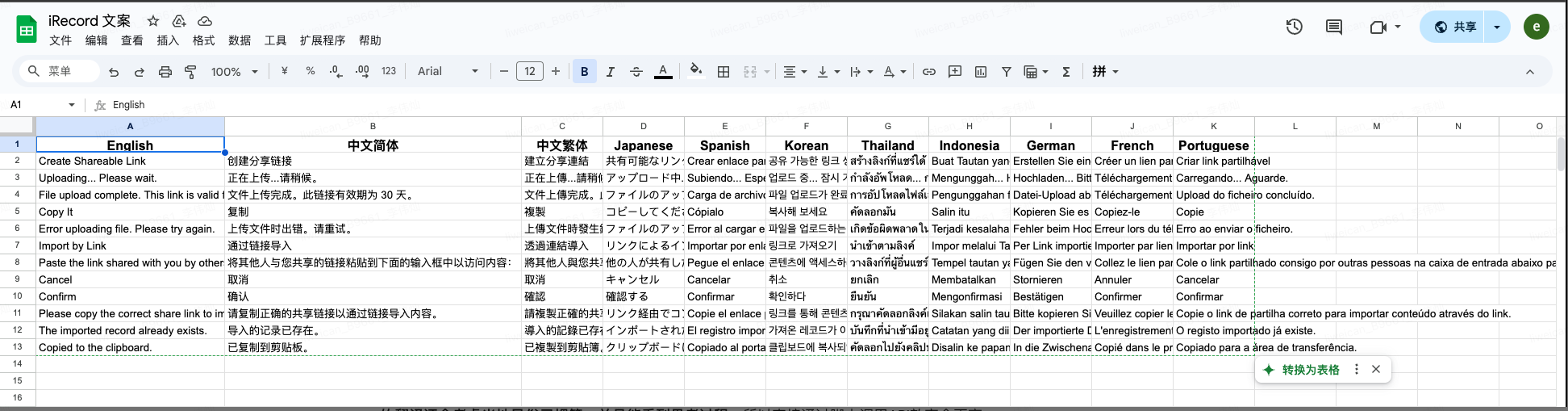
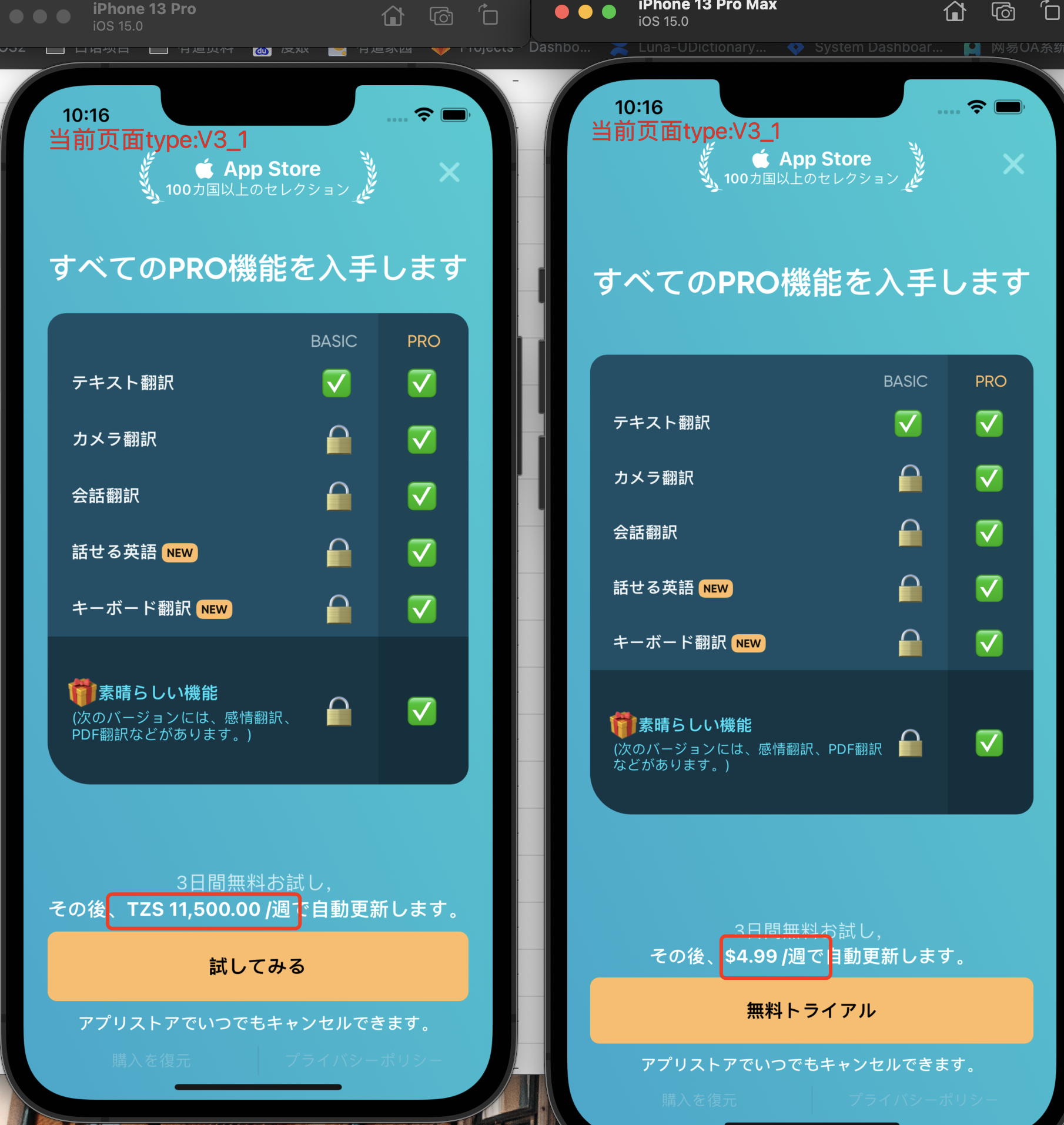
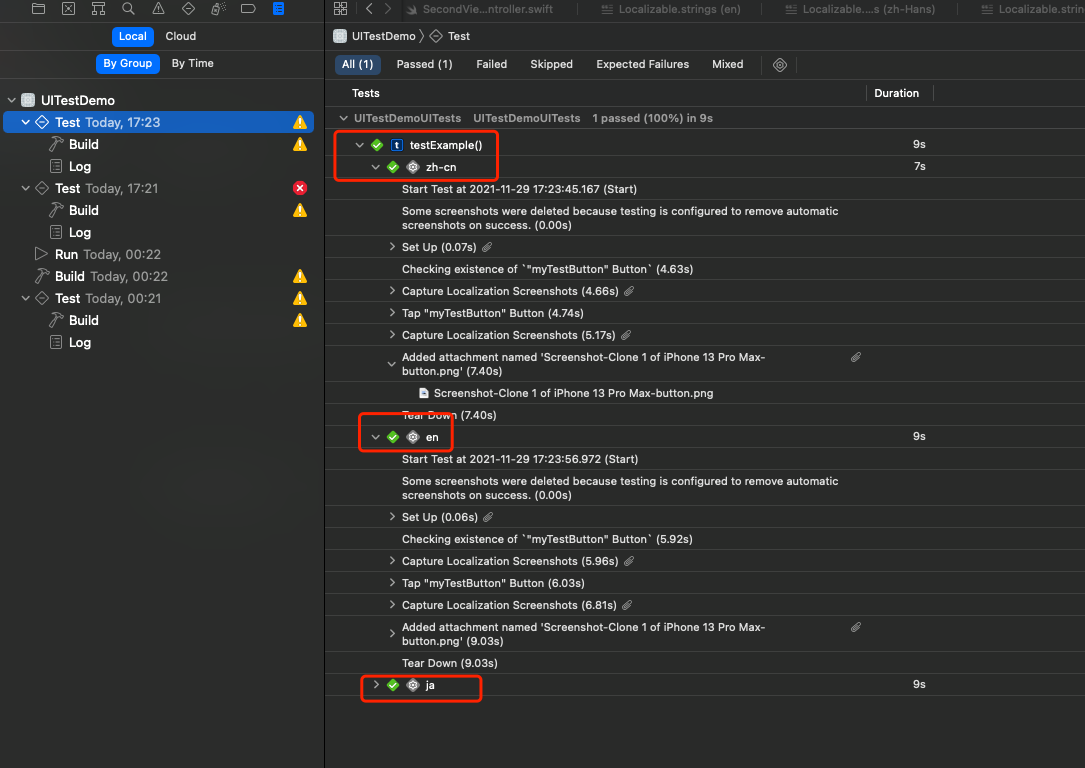
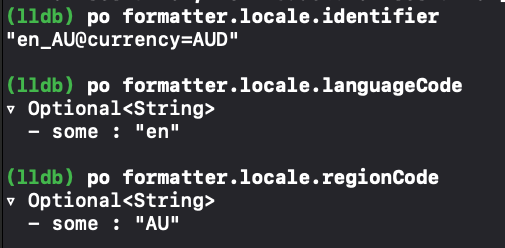
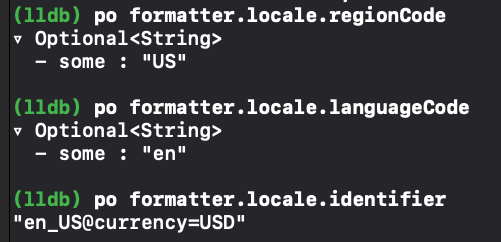
背景
在iOS14.5以后Apple启用ATT(AppTransparencyTracking)。ATT 意味着,如果你的应用程序收集有关最终用户的数据并与其他公司共享以跨应用程序和网站进行跟踪(IDFA),则必须使用 ATT 同意提示并在发布商和广告商应用程序中获得用户同意。如果不跟踪,则无需显示提示。

ATT政策正在加速移动广告行业跃变,用于广告追踪的 IDFA 或将逐渐淡出历史舞台,至此iOS进入后IDFA时代。
Apple给出的解决方案正是SKAdNetWork(SKAN),但是SKAN并不是iOS14.5之后才发布的,SKAN 1.0是Apple于2018年推出的API,在iOS14.5推出ATT后推出2.0。后续更新到了3.0版本,在iOS16.1后推出了全新的SKAN 4.0版本。
大规模的使用是在SKAN 3.0版本,我们也是在3.0版本开始接入。下面先简单介绍下SKAN归因的原理。
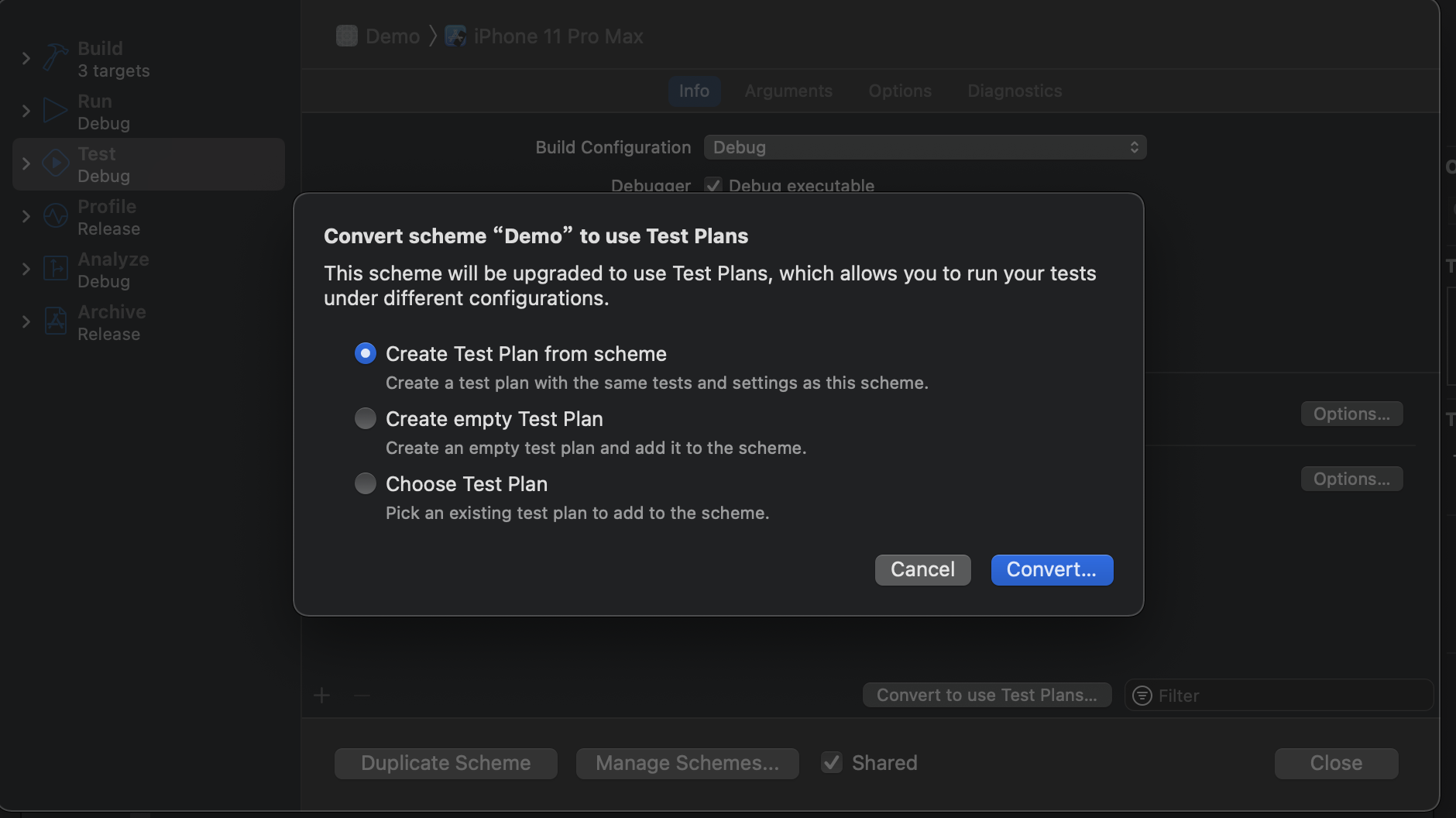
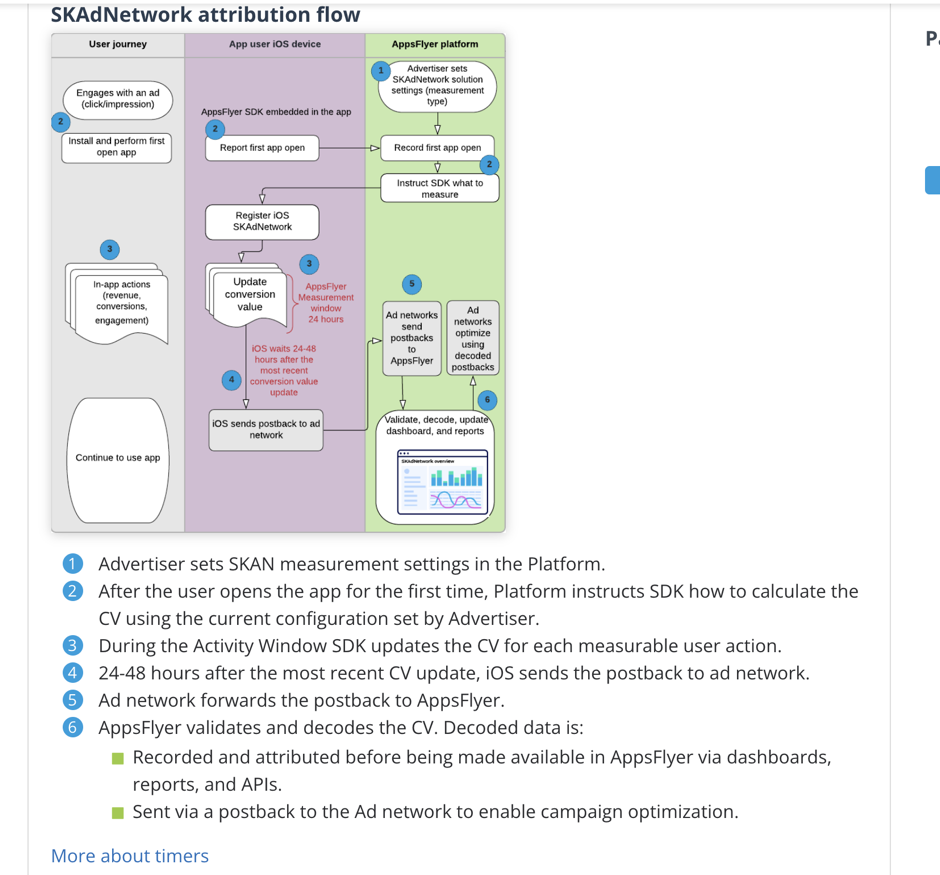
SKAN3.0归因流程
下面是归因的流程图,看不懂没关系,先搞明白几个概念。
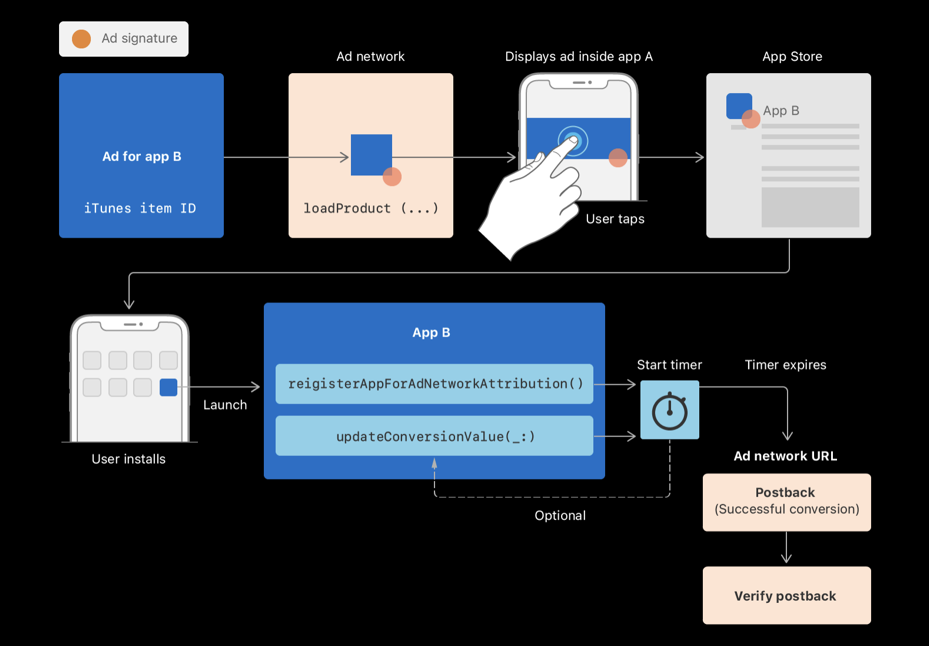
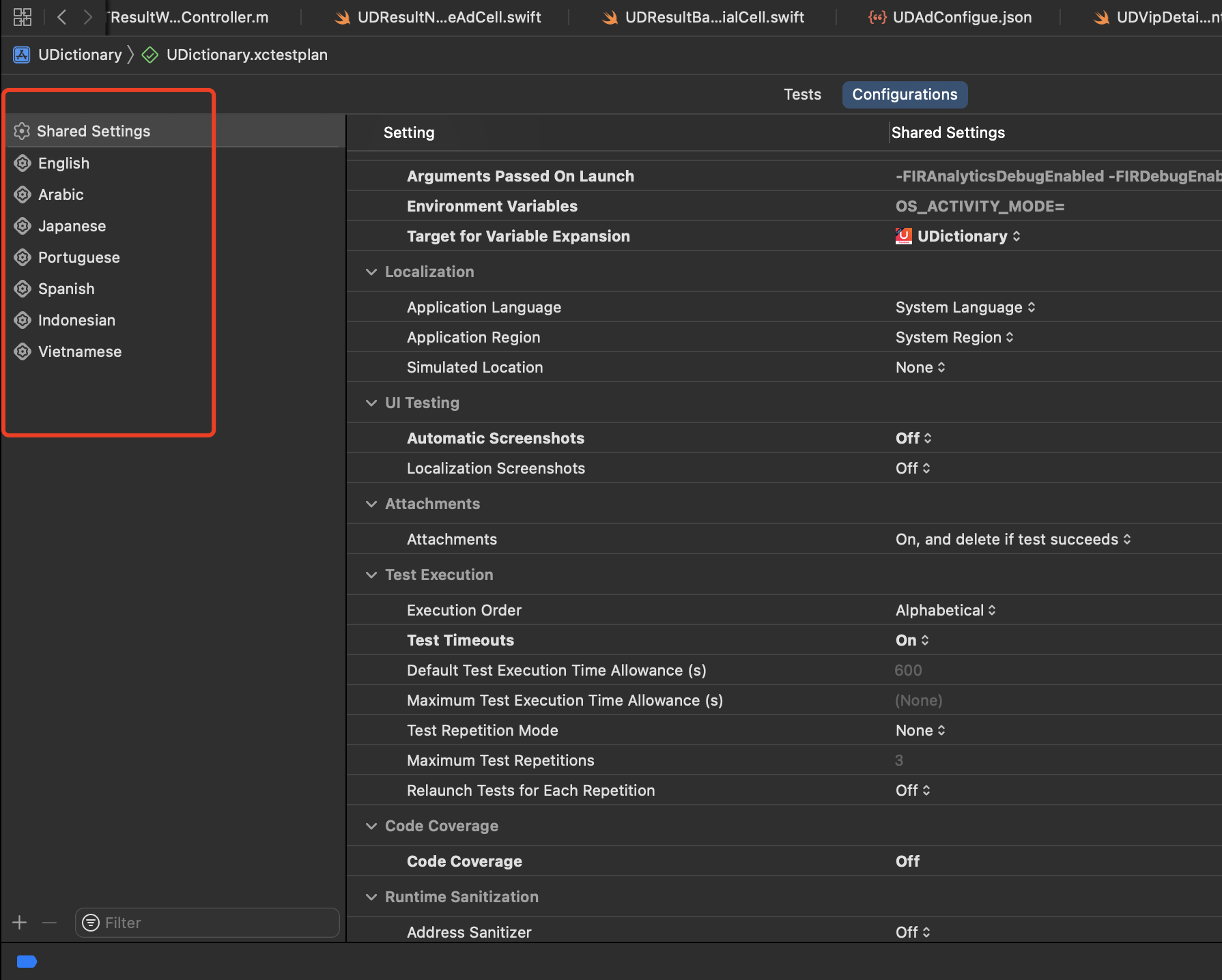
1.Conversion value (CV)
上图有2个方法registerAppforAdNetworkattribution()和updateConversionValue(:_)
updateConversionValue(:_)提到了ConversionValue就是归因的重点。
你可以理解成Apple最后回传给广告主的就是这个CV值,取值范围在0-63之间。
为什么是0-63呢,因为这个CV是一个6bit的值,在二进制中取值范围中就是0-63之间。

SKAN的重点就是合理利用这个64个数
CV值是可以更新的,调用updateConversionValue即可更新。但是新的值必须比旧的大,否则不生效。
2.计时器挑战
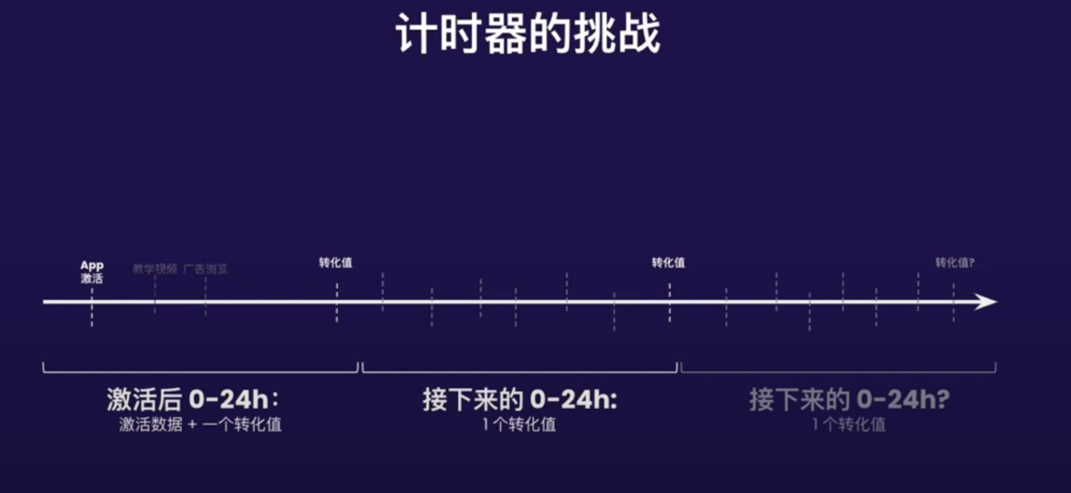
Apple在SKAN中设计了一个计时器功能,App首次安装时候首先调用registerAppforAdNetworkattribution()
开发者可以在24小时的循环周期内反复调用updateConversionValue: 去更新转化数值。
调用此方法有两个目的:
产生一个安装通知,是一个加密签名的数据包,用于验证是否来自广告
应用提供或更新一个转化数值
每次更新CV值成功,计时器延迟24个小时。
如果24小时内CV都没更新,则确定了最终的CV值,最终值确定后,又会在24小时之内把CV值回传给广告平台。
也就是说安装激活转化值在最快会在24-48小时内回传给广告主。
如何理解?安装的CV值都是0,用户安装24小时都没有触发CV值更新,24小时后计时器停止,最终CV值就是0,而Apple又会在24小时内postback,也就是再加0-24小时之间的时间,那就是24-48小时。
这在用习惯IDFA归因看来简直效率低下,之前IDFA归因广告投放后用户安装后立刻就能知道,而使用SKAN最快也要24-48小时之后才知道安装数(还不包括后续CV更新,只看激活数)
举个极端例子,如果CV值对应的转换事件设置不恰当,用户从0一直更新到63,那么你要在60多天后才拿到这个用户最终的CV值。
3.隐私阈值
看了上面的计时器觉得SKAN已经很难用了吧,别慌,还有一个更坏的消息。CV值最终是否传递给广告主还要看用户的行为是否满足Apple的隐私阈值。
这是阈值具体是什么呢?抱歉,Apple没说,一切都是黑盒。
(在我们接入过程中有广告主试了下,得出的大概结论是每个广告系列平均每天安装120个以上才符合,但是很快Apple又调整了隐私阈值)
如果不符合阈值呢,那Apple会回传给你一个Null。
而经过我们测试,新开的广告系列或者效果一般的广告,不符合隐私阈值拿到CV值为null的占比高达90%

SKAN技巧及坑
了解了SKAN的原理,那么说一下SKNA的优缺点。
Apple说优点有很多,我都放下面这个图里了,在隐私越来越严格的背景下,可以预见SKAN在很久一段时间都会是常态。

缺点呢,有很多,最重要的一条就是时效性太差太差。
这对整个团队也是一种考验,作为研发人员,你不但要深入了解SKNA原理,还需要了解各个广告平台,MMP平台的SKNA解决方案(每个平台方案都不同),还要让投放、产品、市场都了解和使用SKAN,合理利用64个CV值的映射,这无疑也是个挑战。
1.使用MMP平台
广告归因平台(Mobile Measurement Partner,简称MMP),SKAN归因特别复杂,所以一般都使用MMP平台来集成,MMP平台去对接各大广告平台,和各大广告平台的SKAN方案做桥接可以做到只设置一个CV映射表对应所有广告平台。
拿我们使用的AppsFlyer平台举例,他们的CV映射方案如下:

具体来讲有分为几个大的维度
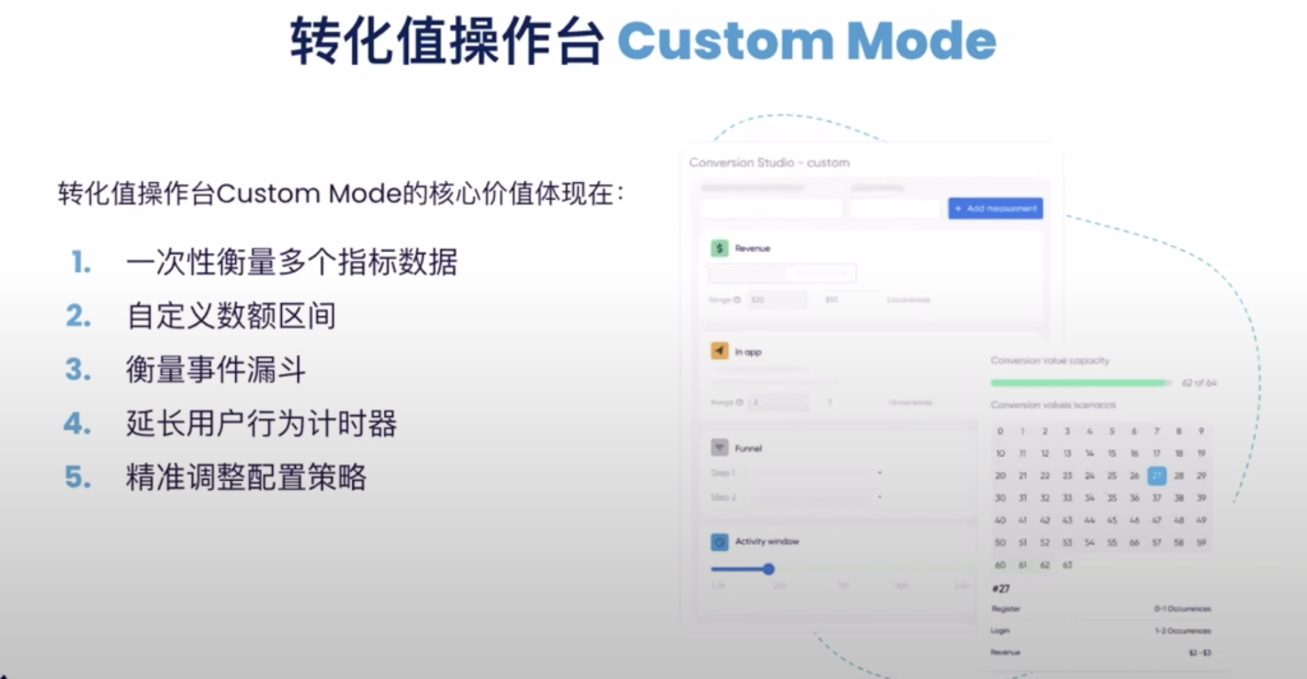
更多信息可以去对应的MMP平台查看。
下面是整个MMP平台和广告平台归因流程。
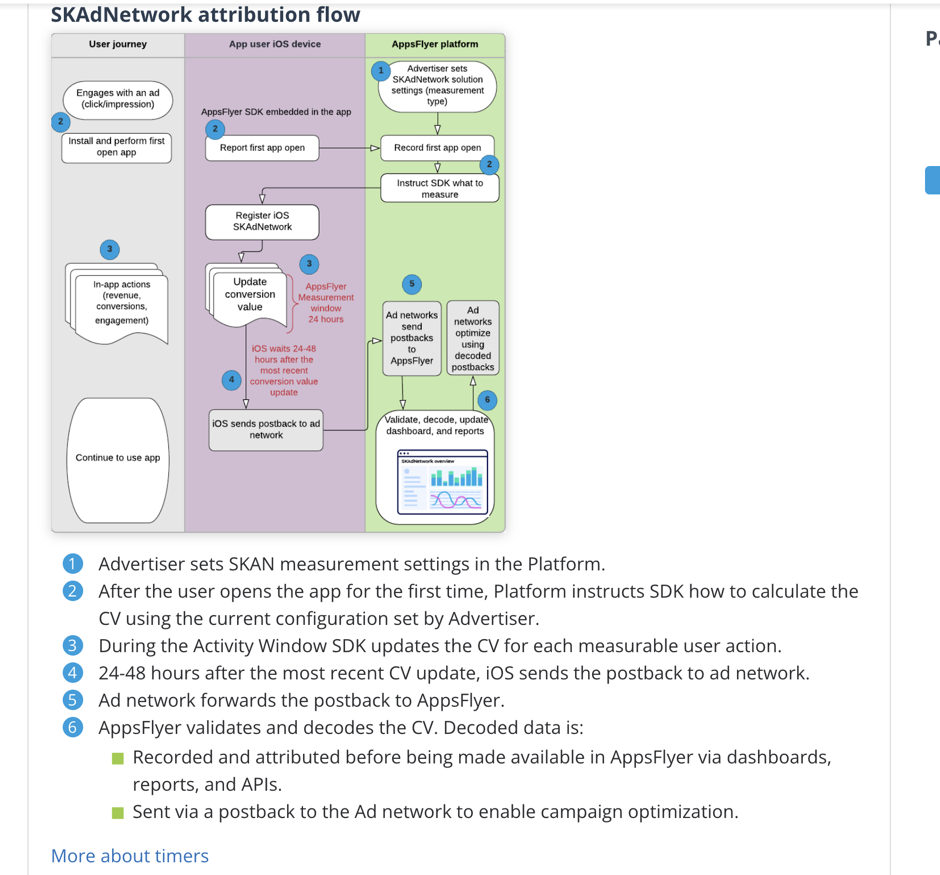
2.合理设置CV值
在MMP平台,可以设置CV映射表,一般就是应用内事件、订阅收入等。
那么如何理解CV值的,拿下图来说,我们统计了
1.收入价值,分了4个范围(对接FB要求必须4个范围,实际可能用不到这么多)
2.应用内事件subs_success
3.归因窗口期
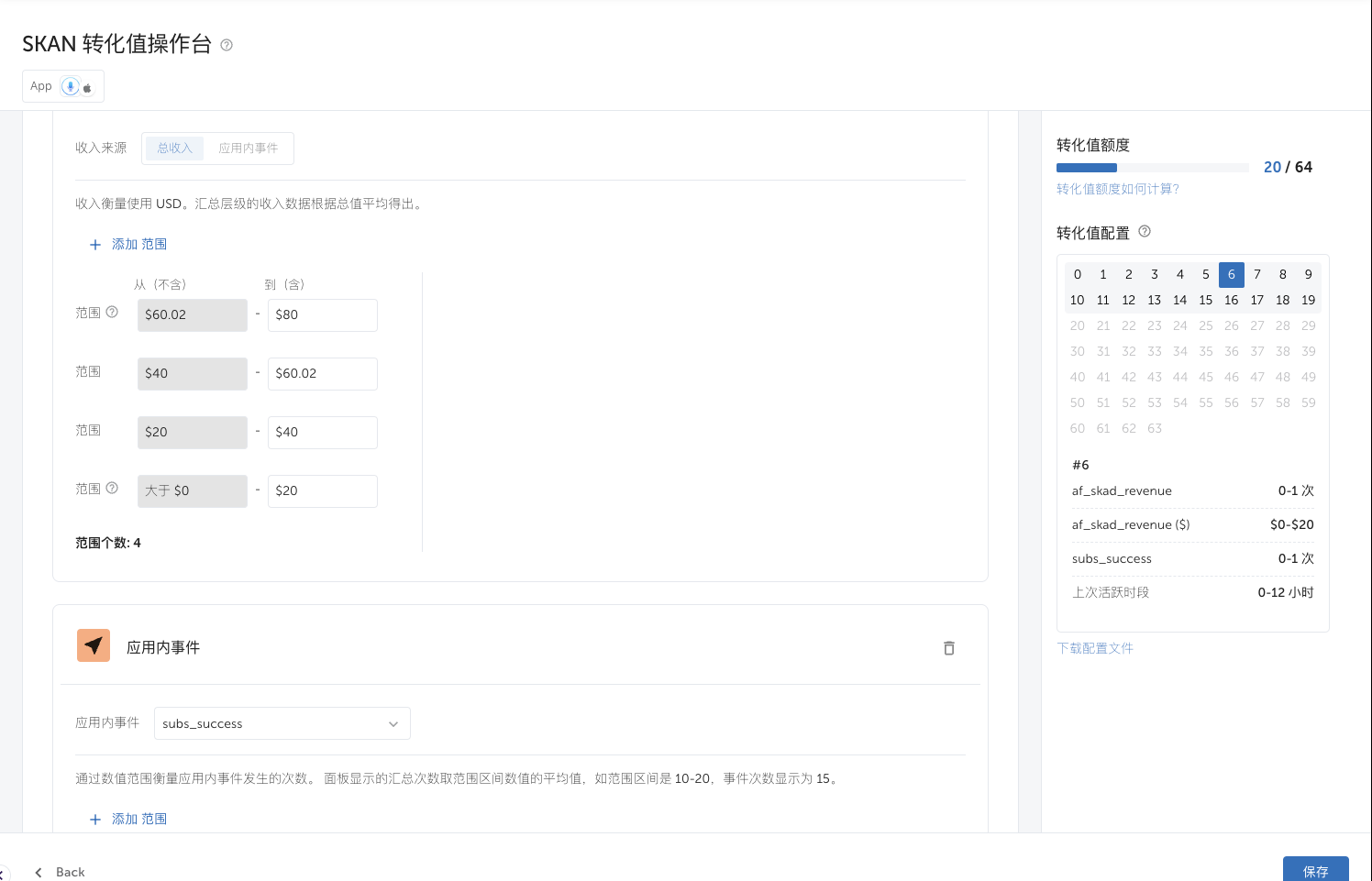
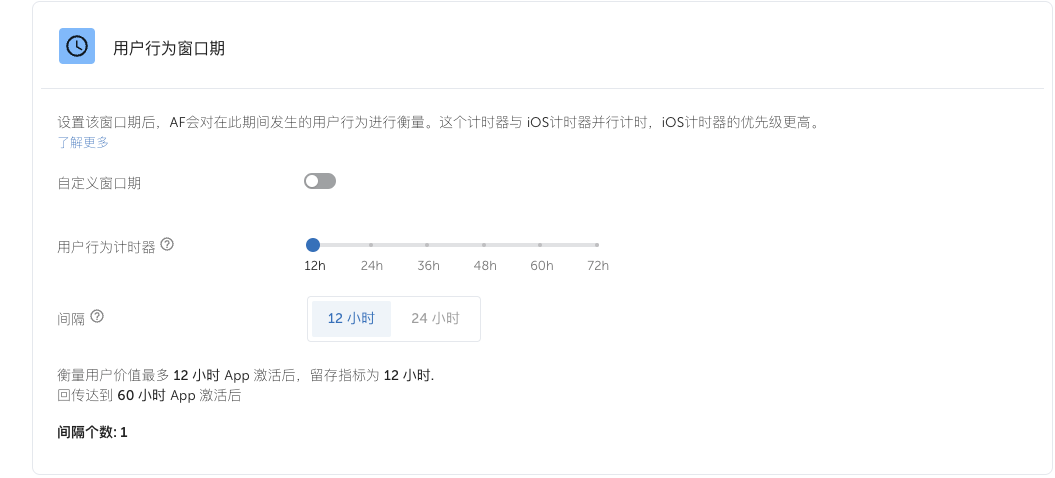
我们会在subs_success事件上报一个事件价值(价值是取平均值,比如你上报的价值落在0-20之间,MMP平台统一统计为10美金),那么CV值=6就代表:用户在激活后0-12小时之内订阅了,产生了subs_success事件,事件价值10美金。
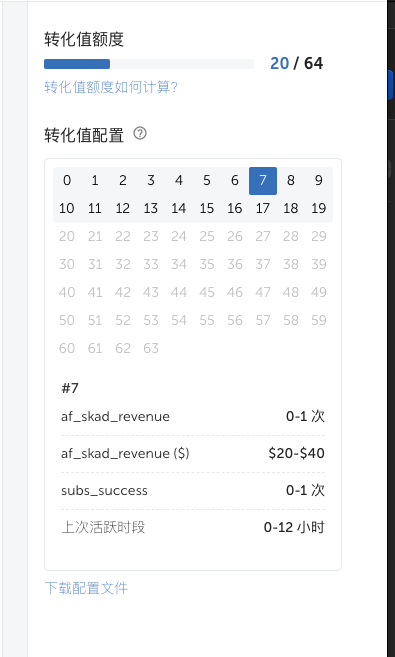
那么7就代表用户在激活后0-12小时之内订阅了,产生了subs_success事件,产生了(20+40)/ 2 = 30美金的价值。
3.各广告平台事件映射
MMP和各个广告平台对接方式都不一样,这里不再展开讲,需要注意的就是CV映射值的调整,在部分平台同步生效需要36-48小时不等,更改CV映射表期间应该暂停广告并且新旧映射表交替时候数据会有部分混乱。
具体看MMP平台文档。
另外还配到一些映射不上,无法拉取成本等等问题,有些是广告平台的问题,需要督促MMP平台找广告平台解决。
这里补充下,MMP平台和广告平台CV值怎么同步的问题。
重点就是你在Google投放的广告,Apple会把最终CV值给Google,比如CV=6,Google要么会从MMP拉取一份你配置的CV映射表,要么回去MMP问CV=6代表什么。同时把CV=6发送给MMP,MMP再在面板上展示数据。
还有提醒一下,MMP平台的SKAN策略和广告平台的会不一致,拿Google来说,Google后台可以Apple给的CV值,但是Google还有自归因逻辑,存在null的情况下GG会自归因判断是否激活。CV值和MMP最终对不上。
那么有的同学就发现这里存在漏洞,既然是Apple给广告平台,广告平台再给MMP,广告平台会不会篡改CV值呢。
因为有些平台结算是按激活量的。这个就是下面要提的交叉验证了。
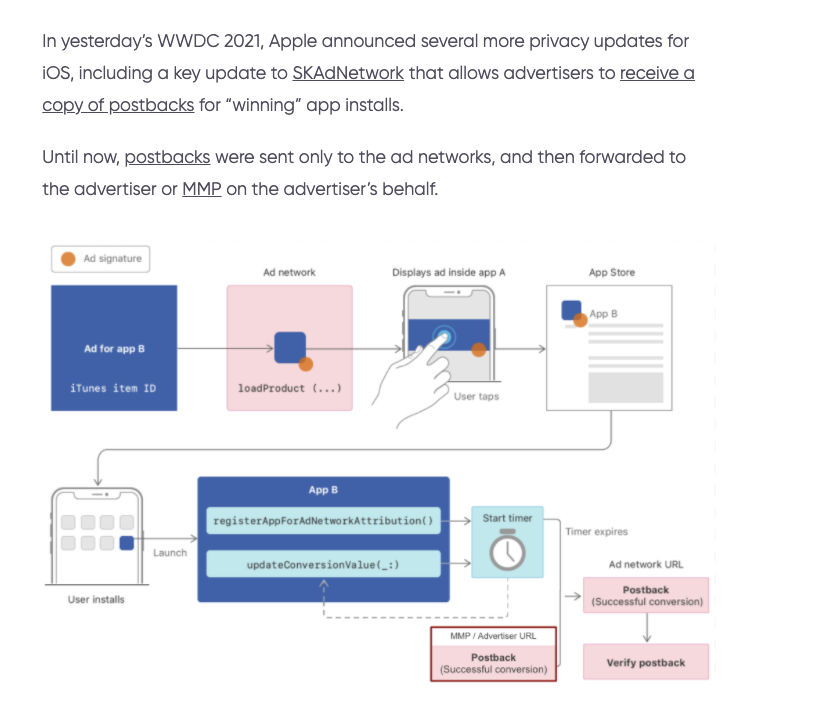
4.MMP交叉验证
Apple在iOS15推出了新功能,可以在发送CV值给广告平台时候,同步发送给另外一个地址。这样就杜绝了广告平台欺诈的情况。
4.成绩
其实对SKAN的介绍要想说透彻必须单开一篇文章来讲了。
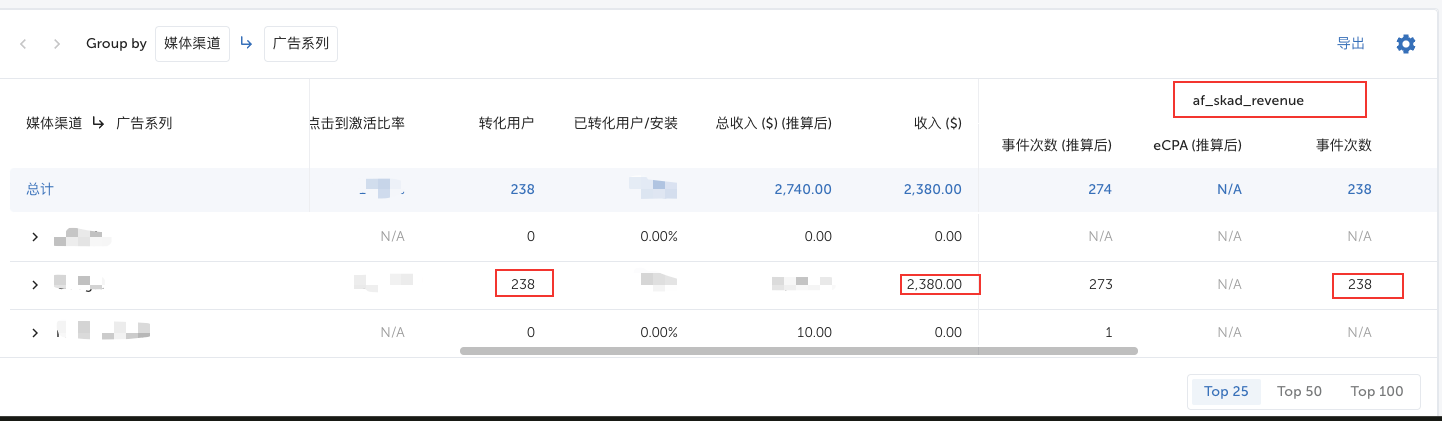
下面说下我们的成绩,截止到SKAN4.0之前,SKAN的归因数据肯定不真实的,为什么?因为隐私阈值的存在,数据相当于抽样。
但是每个平台都抽样,只看绝对值还是能对比那个广告渠道转换和收益好的。
期间也经历了MMP平台CV值混乱bug等等,但是总体来说SKAN是目前最优解决方案。
目前我们一个订阅上报10美金价值,数据去除隐私阈值的损耗,看整体趋势也能和Apple后台数据对得上。
除了SKAN,还可以使用Apple官方的ASM(App Store Search Marketing )又名 ASA(Apple Search Ads)。ASM并不使用SKAN,而是传统的归因(果然好东西还是留给自己平台)。
关于更多SKAN4.0的信息,我会单独开一篇来讲。