背景
国际词典团队致力于打造高质量出海工具类App产品矩阵,目前旗下有
- 词典翻译类: U-Dictionary、One Translate
- 语音转写类:iRecord、iTranscribe
- 电话录音类:iCall Record
在2022年底,iOS端需要开发一个新的文档扫描类产品:iScanner,此类产品在安卓端已经验证了商业化可行性。
开发时间只有短短几周,需要快速进行技术调研和方案确定。
核心功能就是用户使用相机拍摄或相册选择图片,自动框选出图片内的文档轮廓,裁剪后进行方向矫正。
拿到矫正后的图片调用有道自研的文档增加接口和手写擦除接口。
先看一下最终实现效果:
技术选型&实现
客户端需要实现的核心功能有2个:
- 文档角点检测
- 图片方向矫正(透视矫正)
1.角点检测
自研SDK
安卓端的方案:
- 文档脚点监测使用算法端提供的自研SDK,底层模型使用C++实现,推理框架用的MNN(Mobile Neural Network)
- 图片矫正使用的是opencv的透视变换
不幸的是自研模型并没有提供iOS端的SDK,底层使用C++需要自己桥接下提供相关的接口。
有道还有一套在线的文档角点检测服务,但是考虑到海外网络环境复杂,最好还是使用离线的。
当然opencv也提供角点检测的能力,但是识别率太差不在考虑范围内。
那么iOS端有原生能力支持吗?其实熟悉iOS的应该都知道iOS系统备忘录是提供文档扫描的,并且效果很好。
系统内的备忘录支持多张图连续扫描,支持脚点监测和图片方向矫正。
Apple也开放了接口供开发者使用,那就是VisionKit下的VNDocumentCameraViewController
VisionKit
VisionKit是iOS13推出的,为 iOS 提供了图像和实时视频中的文本、结构化数据的检测功能。
VisionKit本质上是对Vision的封装,
而VisionKit下VNDocumentCameraViewController是可以直接使用的,效果如下:
其内置了脚点自动检测,脚点拖拽调整等交互。支持从视频buffer流中直接检测。
但是VNDocumentCameraViewController封装的非常死,无法修改内部任何UI和交互流程,所以只能pass
更多关于VisionKit的信息参考:
Visionkit Documentation
VNDocumentCameraViewController
Vision
既然VisionKit是基于Vision的封装,那么完全可以基于Vision自己来实现所有功能VNDocumentCameraViewController刚推出时候当时的底层技术是基于Vision的VNDetectRectanglesRequestVNDetectRectanglesRequest会监测图片中所有矩形并返回一个数组,依赖VNDetectRectanglesRequest再加上后期算法,是可以进行文档检测的。
但是Apple在iOS15时候发布了新APIVNDetectDocumentSegmentationRequest
看API的名字就能知道是针对文档进行了单独优化的,那么VNDetectDocumentSegmentationRequest比VNDetectRectanglesRequest厉害在哪里呢?

如上图所示,同一张图片,VNDetectRectanglesRequest检测出了所有矩形,而VNDetectDocumentSegmentationRequest准确的检测出了文档。
在底层技术上,区别如下:
DocumentSegmentation基于机器学习并且能够运行在NE(神经网络引擎),CPU或者GPU上面,而VNDetectRectanglesRequest只能在CPU上运行,运行速度上就拉开了很大差距。DocumentSegmentation还能识别出非矩形形状的文档,还能提供mask和顶角点坐标。
更重要的是VNDetectDocumentSegmentationRequest只会识别出一个文档而不会检测出多个矩形,这无疑减轻了很多工作量,可以直接拿来使用。
另外,
Visionkit中的VNDocumentCameraViewController底层技术,在iOS15之后也已经替换成了VNDetectDocumentSegmentationRequest
VNDetectDocumentSegmentationRequest
VNDetectDocumentSegmentationRequest的使用非常简单
func recognize(image: UIImage) -> VNRectangleObservation? { |
注意:
在传入图片前请处理好图片的imageOrientation
VNImageRequestHandler也支持ciImage的初始化,可以合理选择使用方式
在result中会返回一个置信度,一般设置大于0.7就认为识别有效,具体参数可以动态调整。
返回结果是VNRectangleObservation类型
|
之前用过Vision的同学肯定很熟悉父类VNDetectedObjectObservation,在VNDetectedObjectObservation中有一个boundingBox熟悉
/*! |
boundingBox 中的坐标被归一化,意味着 x、y、宽度和高度都是 0.0 到 1.0 之间的小数,同时原点 (0,0) 在左下角,这些都需要我们自己来转换。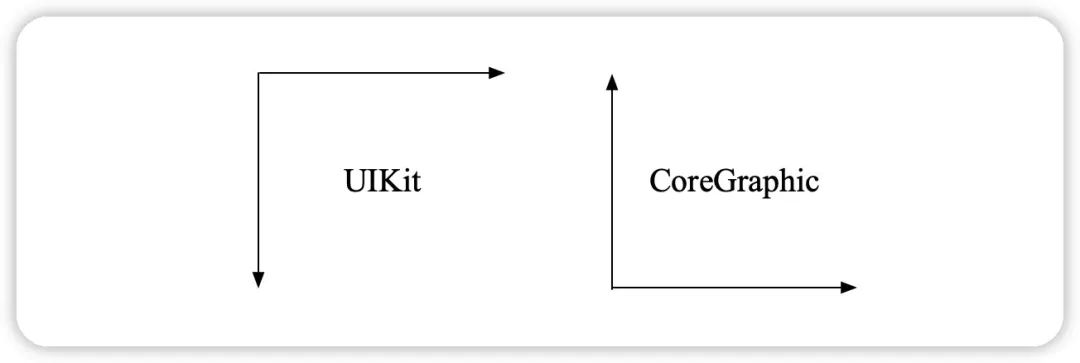
同样在文档角点检测中返回的四个脚点topLeft,topRight,bottomLeft,bottomRight,也是归一化的,起点在左下角,需要进行坐标转换后才能在图片上展示识别框。
这里有一个小技巧,先把原图进行imageOrientation处理和尺寸压缩,展示在屏幕上后建立一个和展示image大小一致的CALayer图层,后续框体展示、拖拽、旋转等都方便处理。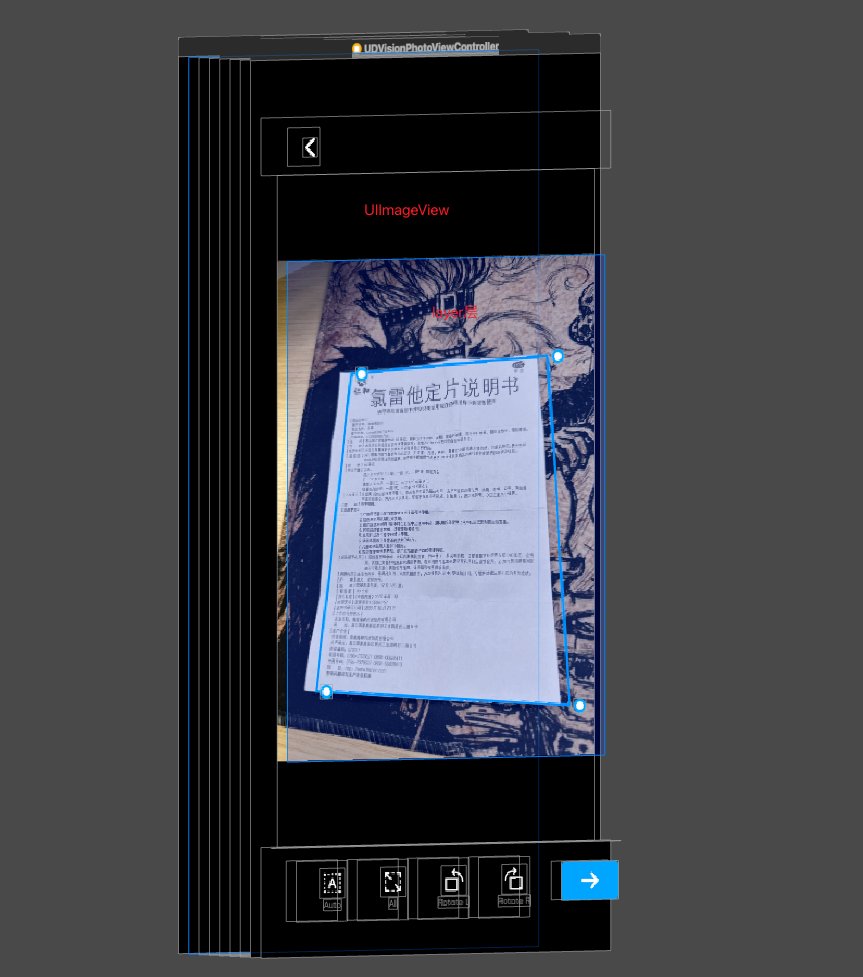
坐标转换代码
let size = self.pathLayer!.bounds |
当然只是框选出来文档框架才是第一步,用户还能拖拽脚点编辑框选区域。所以坐标点还需要反向转换。
做框选中,还需要判断矩形是否有效(内角是否大于180度),可以根据对角线 ac 和 bd 对角线是否交叉 根据叉积(向量积)计算
差积算法
private func checkInnerAngleAvailable() -> Bool { |
那么脚点监测的最终方案也定下来了,下面来看一下各个方法的识别对比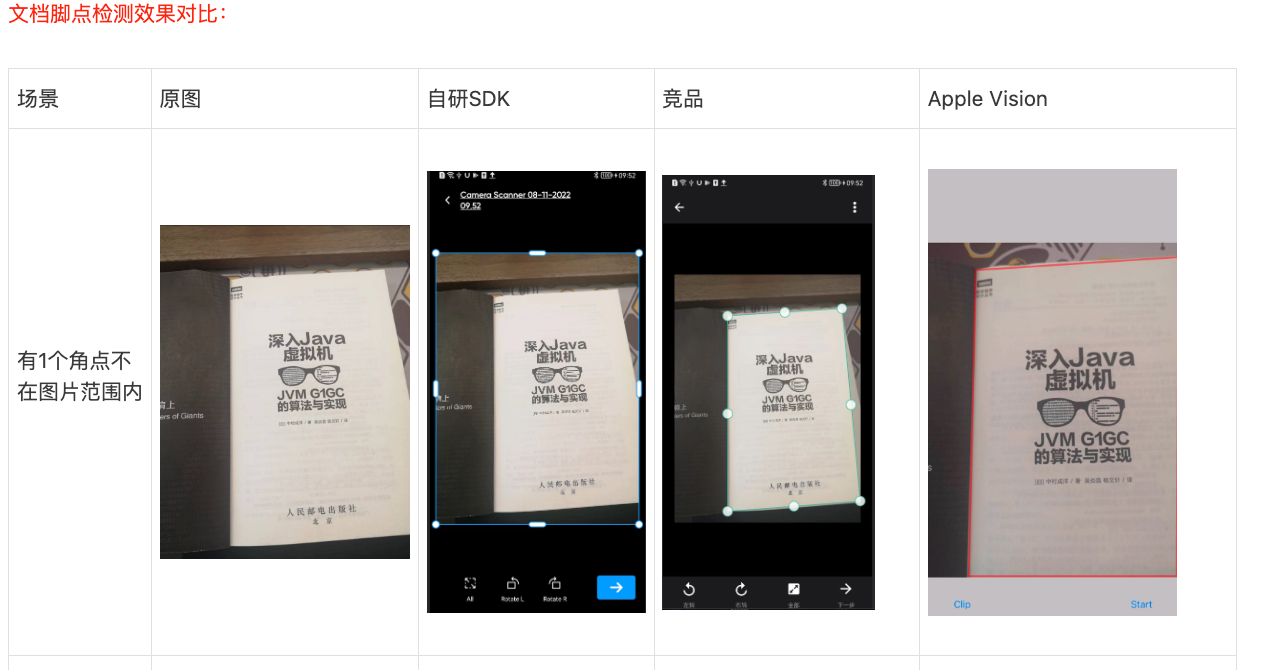
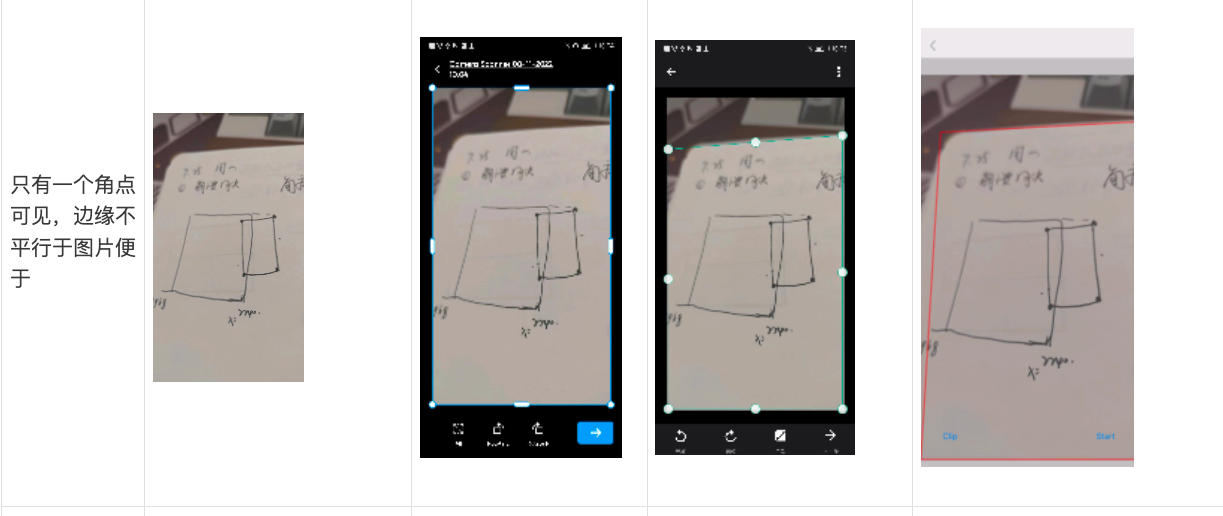
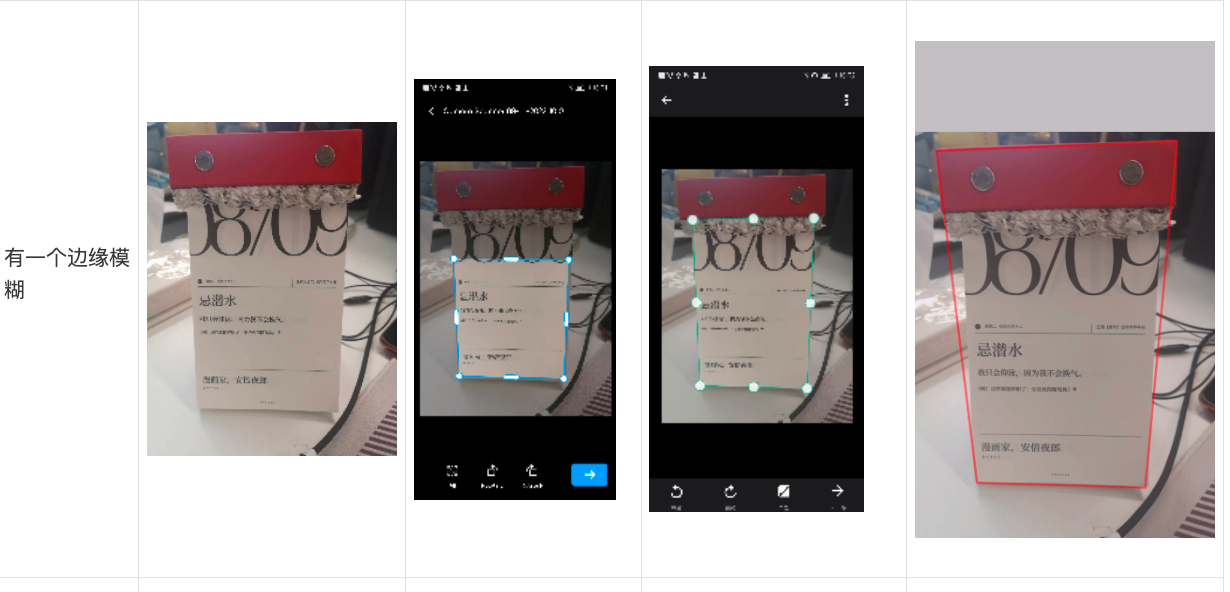
可以看到Apple Vision下的
VNDetectDocumentSegmentationRequest检测效果是优于自研模型的,部分badcase效果还超过也竞品。
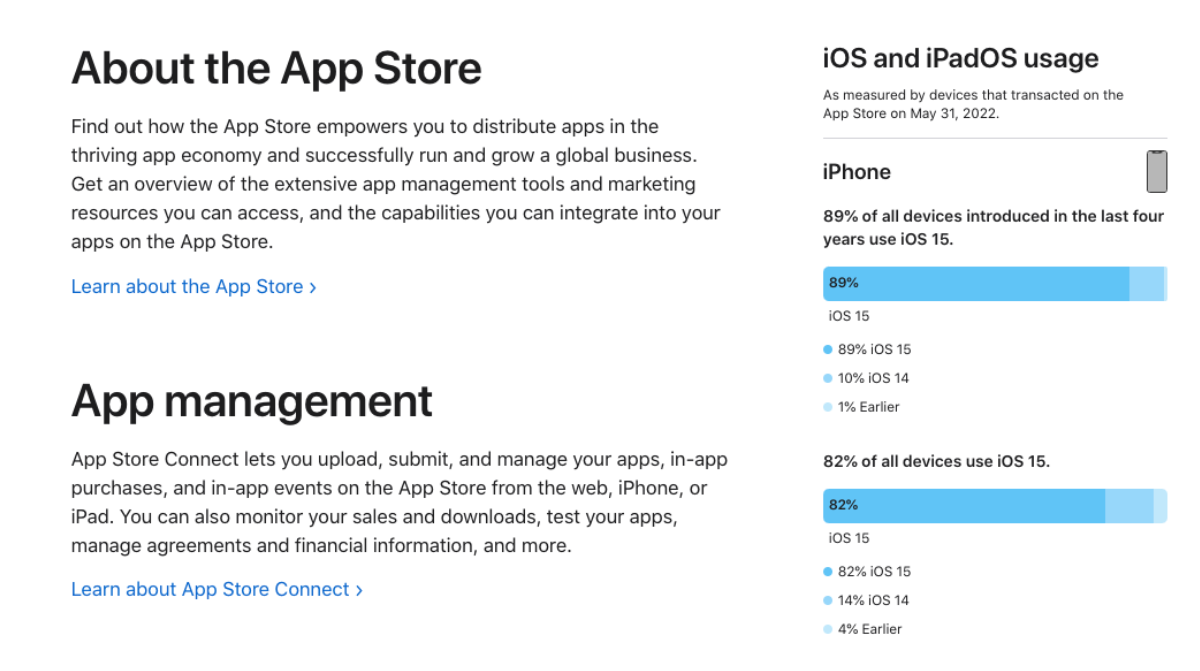
当然唯一的限制就是iOS15+才能使用,但是参考Apple提供的系统占比数据,截止到2022年5月 iOS15以上占比89%
update:
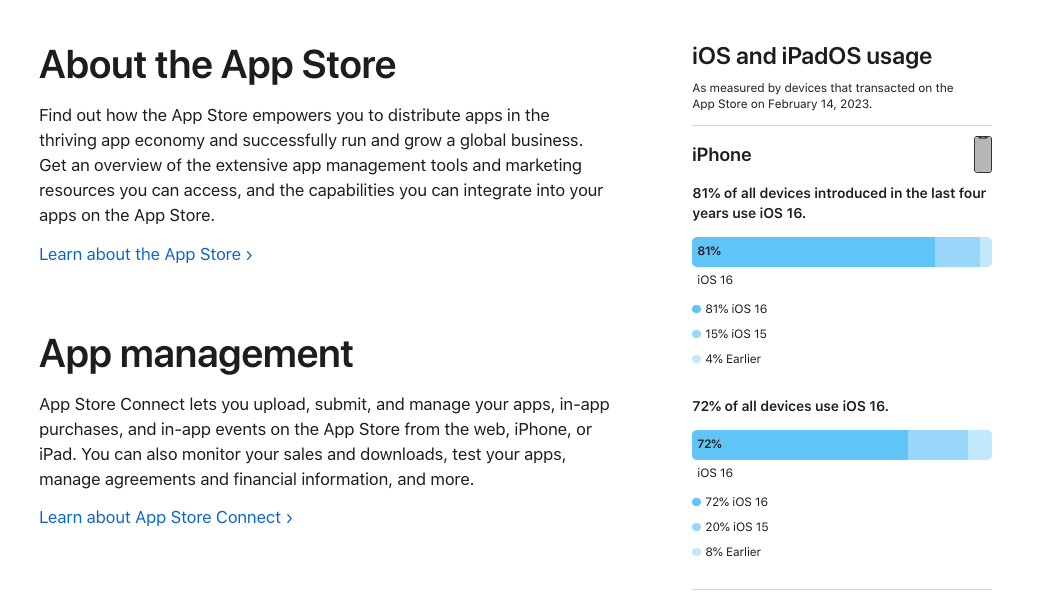
Apple在2023年2月14日公布了最新数据,iOS15以上占比96%
到此已经完成了文档角点检测,接下来要解决图片视觉矫正。
2.透视矫正
图片矫正(透视矫正)在OCR中广泛使用,主流做法就是使用opencv进行处理。
原理有很多,一般是边缘投影的、Hough变换、线性拟合,傅里叶变换图像频域等方法。这里不再展开讲了。
并且opencv里面常用的是矩形监测和矫正一起,我们在第一部分已经完成了角点检测,只是做矩形矫正就没必要再用opencv了。
Apple VisionKit中的VNDocumentCameraViewController是支持方向矫正的,那么Apple自身提供的API应该是可以实现的。
那提到Apple内置的图像处理,肯定就绕不开CoreImage了
CoreImage可以实现多种多样的滤镜效果,滤镜一般基于CIFilter,在CIFilter中就有现成的矩形矫正算法。
更多关于CoreImage的信息参考:
Core Image
CIFilter
CIFilter
要实现矫正,首先要把角点检测后4个点形成的图片裁剪出来。4个点是归一化后的,先把图片进行CIImage转换,调用cropped方法进行裁剪。
func clipAction() { |
拿到裁剪后的图片,就可以进行透视矫正了,iOS中透视矫正使用CIVectorCIVector需要搭配CIFilter使用,可以产生丰富的效果
圆形缠绕过滤器
let newImage = applyingFilter(CICircularWrap, parameters: [kCIInputImageKey: image, kCIInputCenterKey : CIVector.init(x: 100, y: 200), kCIInputRadiusKey : 20, kCIInputAngleKey : 3]) |

边缘采样过滤器
applyingFilter("CIEdgePreserveUpsampleFilter", parameters: [kCIInputImageKey: image, inputLumaSigma : 0.15, inputSpatialSigma : 3, inputSmallImage : image2]) |

而我们要使用的就是矩形矫正过滤器CIPerspectiveCorrection
下面是做的一个Extension,只需要传递四个还原后的坐标即可完成矫正
extension CIImage { |
看一下矫正效果
至于其余功能比如最小裁剪大小,旋转,镜像等功能就不再讨论了。至此已经完成了文档扫描的核心功能。
优点有很多
- 纯离线,无网络要求
- 角点检测速度快,能运行在GPU上
- 纯原生支持,不依赖三方库
- 效果优于自研SDK
iScanner目前已经上线,欢迎大家去体验,如果有其他疑问也可以和我联系
李伟灿
网易有道-国际App
liweican#corp.netease.com
感谢阅读~